AniPic
AniPic is an AI-powered platform for semantic categorization and indexing of anime images with advanced search algorithms.
Project Overview
AniPic emerged from the idea of combining the capabilities of modern AI image recognition technologies with a specialized search engine for anime content. The concept is similar to Google Images, but focuses on precise categorization and indexing of anime frames using machine learning.
Technical Architecture
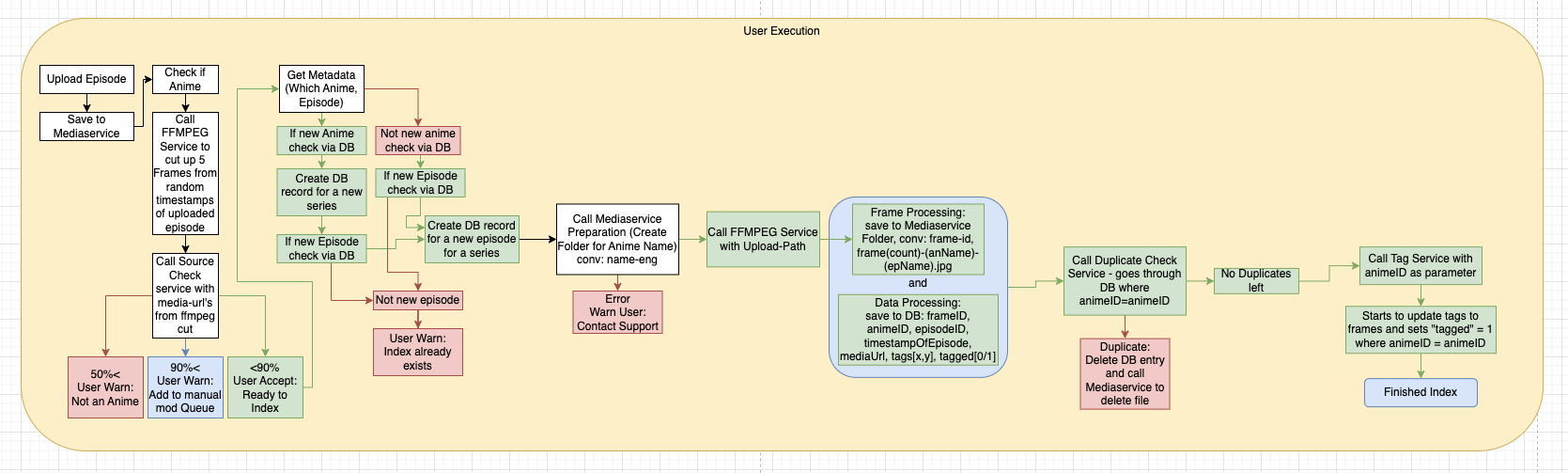
The system workflow was designed as follows:
- Users upload anime episodes through a secure API to the platform
- A content verification system checks the media for validity and compliance
- An optimized FFMPEG process extracts frames at defined intervals
- Each frame undergoes an AI categorization process with semantic analysis
- The categorized data is indexed in a NoSQL database and optimized for search
Technical Challenges
The main challenge was the efficient processing of large amounts of data. With a dataset of approximately 4TB of episodes, an optimized system for frame extraction had to be developed. During implementation, I identified a suboptimal FFMPEG configuration that led to redundant frames – a problem that was solved by adjusting keyframe intervals and implementing a similarity algorithm.
The second major challenge concerns AI categorization. Here I'm evaluating different approaches:
- Integration of a pre-trained vision-language model like CLIP
- Utilization of the OpenAI API (GPT-4 with vision capabilities)
- Development of a specialized model with transfer learning on anime-specific datasets
Current Development Phase
Currently (as of October 2023), the project is in the data preparation phase. The extracted frames are stored on a dedicated storage cluster and await implementation of the categorization system. The next steps include finalizing the AI component and developing the search functionality with Elasticsearch.
Legal and Ethical Considerations
A significant aspect of project planning was addressing copyright issues related to the use of anime frames. The system was designed to operate in accordance with fair use provisions by focusing on metadata and transformative use rather than reproducing entire episodes.
Technologies Used
- Python for backend processes and ML integration
- FFMPEG for media processing
- MongoDB for data storage and indexing
- NextJS for the frontend
- TailwindCSS for responsive UI components
- Docker for containerization and scaling
Planning
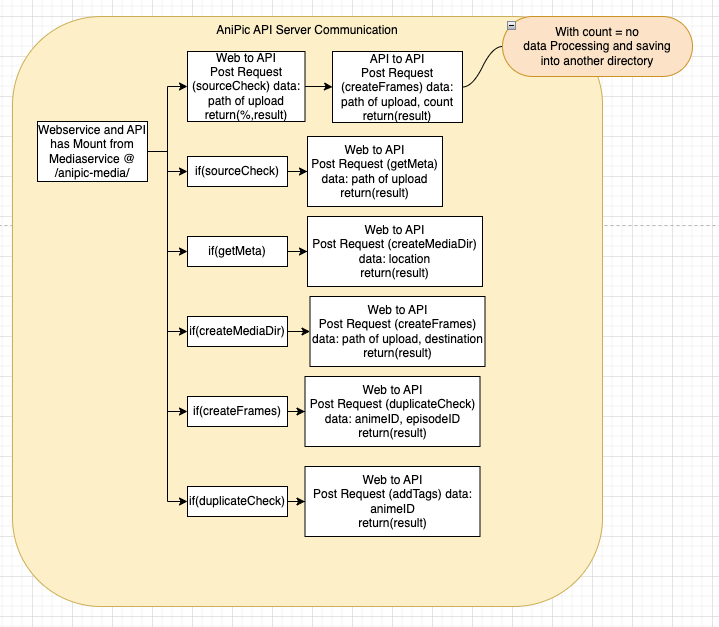
The system architecture was modeled with Draw.io and includes detailed flowcharts for various processes:
For server communication: